COMPARAZIONE VOCALE
Di tutti i servizi offerti dal nostro studio, viene di seguito approfondito il più rappresentativo: la comparazione vocale per il riconoscimento del parlatore, argomento richiesto in sede giudiziaria. Nel campo della pratica forense, intendiamo per comparazione vocale la verifica tecnica del livello di uguaglianza tra due voci. In ambito giudiziario, le due voci da comparare sono generalmente appartenenti a un parlatore noto, nella figura dell’indagato, e a un parlatore anonimo la cui voce è stata registrata in un’intercettazione telefonica o ambientale. Prima di procedere con qualsiasi operazione, è necessario effettuare una diagnosi qualitativa e quantitativa dei file audio disponibili.
(Per vedere l’elenco di tutti i servizi effettuati su registrazioni audio e perizie foniche si veda questa pagina)
In diverse occasioni, in particolar modo per intercettazioni e registrazioni ambientali, è opportuno prima provvedere ad una pulizia dei disturbi presenti nella registrazione per poi procedere con l’eventuale comparazione, trascrizione, verifica del parlante e quant’altro necessario per effettuare una corretta perizia fonica ad uso forense. Inoltre, anche la voce nota dell’indagato potrebbe provenire da una registrazione telefonica o ambientale di bassa qualità e sarebbe consigliabile perciò effettuare un saggio fonico di alta qualità, ovvero una registrazione vocale fatta all’indagato presso il nostro studio oppure presso il luogo di detenzione se egli non si trovasse in stato di libertà.
Zoom H6 recorder

Prima di procedere con la comparazione, è necessario fare alcune premesse relative alle caratteristiche della voce e del parlato. L’onda prodotta dalle vibrazioni delle corde vocali ha una struttura composta dalla frequenza fondamentale (f0) e corrisponde al numero di oscillazioni delle corde vocali nell’unità di tempo. Tale frequenza (f0) è percepita dall’ascoltatore come tono principale del timbro vocalico. Il valore di f0 dipende dalle caratteristiche anatomiche dell’apparato fonatorio, come la lunghezza e la larghezza delle corde vocali. Più spesse e lunghe sono le corde, più bassa è la frequenza di vibrazione. Questo è il motivo per cui il tono di un uomo è più basso di quello di un bambino. Semplificando, le corde vocali sono lamelle che vengono messe in vibrazione dal passaggio dell’aria. La vibrazione è di tipo impulsivo, e produce una serie di impulsi ravvicinati seguiti dalla risonanza del tratto vocalico, che agisce da cassa armonica. Infatti, senza la risonanza del tratto vocale, le corde non sarebbero in grado da sole di produrre timbri diversi, ma solo altezze diverse.
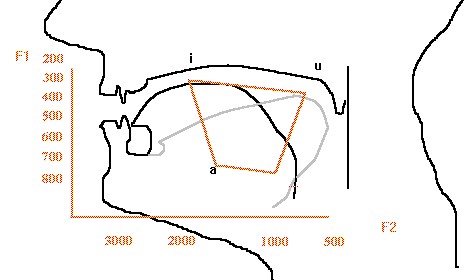
Nella comparazione vocale ci si occupa principalmente dell’analisi dei foni vocalici, proprio perché sono rappresentative del tratto vocalico di risonanza. La loro generazione nell’apparato fonatorio avviene in questo modo: il tratto vocale, che va dalle corde fino alle labbra, costituisce la cassa armonica, che filtra il suono prodotto dalle corde generando le frequenze formanti che compongono il timbro vocalico. Le risonanze che vengono a crearsi sono di complessa e peculiare entità e vanno a caratterizzare quindi in modo pressoché definitivo, per ogni parlatore, la distribuzione dell’energia delle formanti durante la modulazione del parlato. Ogni suono vocalizzato ha quindi una propria caratteristica di configurazione delle formanti. Occorre ricordare che le vocali intese come singoli “foni” sono più di cinque. Se si considerano tutte le forme, aperte, chiuse e con accenti particolari, se ne possono presentare anche più di dieci in base alla lingua del parlante.
Esempio di distribuzione formantica di foni vocalici (Bielefeld University)
I metodi di comparazione vocale utilizzati in ambito forense sono generalmente raggruppabili in tre categorie: metodi soggettivi di ascolto, metodi semi-automatici, metodi totalmente automatici.
Il metodo soggettivo utilizzato per il riconoscimento del parlatore consiste in un esame di ascolto molto attento, effettuato in un ambiente privo di rumori esterni e con cuffie professionali o altoparlanti monitor professionali, in cui il tecnico andrà ad individuare le caratteristiche proprie della voce del parlante e potrà riscontrare eventuali anomalie nella registrazione. Un software utilizzato è iZotope RX6 Advanced, programma standard di riferimento del settore del restauro del suono. Questo software permette di associare all’ascolto un’analisi spettrografica. Lo spettrogramma è un sistema di analisi che consente di verificare il contenuto in frequenza e dinamica di un programma audio nel tempo. È possibile quindi vedere in ogni istante quali frequenze sono presenti e con quale intensità. Questo consente ad un tecnico esperto di “vedere”, oltre che ascoltare, il contenuto audio e confrontarlo con altri segnali. L’uso degli spettrogrammi è di fondamentale importanza al fine di riconoscere eventuali distorsioni, saturazioni, rumori di fondo o interferenze presenti nel segnale.
IZotope RX6 Advanced – Visione spettrografica e forma d’onda
L’analisi soggettiva può permettere, soprattutto in relazione all’esperienza del tecnico, di individuare gli elementi caratterizzanti del parlante, quali ad esempio:
- Timbro e intonazione;
- Posizione degli accenti;
- Velocità di locuzione;
- Durata vocalica e consonantica;
- Variazione intralinguistica e interlinguistica.
Il metodo semi-automatico consiste nell’analisi dei valori delle formanti vocaliche e nel successivo confronto di tali valori per ogni parlatore. Si parla di metodo semi-automatico poiché, pur essendo i calcoli ottenuti tramite software e modelli matematici, è il tecnico che manualmente selezionerà i foni vocalici da confrontare all’interno della registrazione.
Le formanti di un segnale sono funzione delle intensità rilevate in alcune particolari bande di frequenza. La competenza del tecnico consiste nell’effettuare un’accurata scelta del punto di analisi dove stabilire la finestra di acquisizione del campione vocalico. A questa finestra si applicherà un Linear Predictive Coding. LPC è una tecnica di codifica dei segnali vocali, ideata per consentire una digitalizzazione di buona qualità anche con bassi valori di bitrate. LPC si basa su un algoritmo predittivo che codifica il contenuto vocale in modo sottrattivo, ovvero formulando un’ipotesi e codificando solo le differenze che si presentano nel tempo, permettendo quindi un notevole risparmio in termini di informazione da codificare. Tale algoritmo si basa sull’assunzione che una voce sia calcolabile come la modulazione delle corde vocali effettuata dall’apparato fonatorio.
Tra i software che possono essere utilizzati per questo tipo di analisi vi sono ad esempio Multi-Speech 3700 della Pentax Medical, a pagamento, e PRAAT della University of Amsterdam, open-source. Tramite l’utilizzo di questi software, il tecnico procederà a “campionare” i suoni vocalici, ovvero ad eseguire una finestratura sulle sezioni di audio dove sono presenti suoni vocalici, e ad analizzarne le componenti formanti. Le formanti che considereremo sono le prime quattro (f0, f1, f2, f3), le successive hanno minore importanza poiché, crescendo con la frequenza e diminuendo di intensità, si riducono le possibilità di corretta misurazione.
PRAAT – Finestratura di un campione vocalico

Le frequenze formanti (f0, f1, f2, f3) sono frequenze dovute alla struttura delle corde vocali e alle risonanze del tratto vocalico e dell’apparato fonatorio. Diverse configurazioni di quest’ultimo determinano la produzione di differenti formanti. Mentre la fondamentale (f0) è legata alla struttura della cavità faringea e delle corde vocali, la f1 dipende dall’angolo di apertura mandibolare e la f2 è legata alla posizione della lingua che modifica il tratto faringeo.
Si può procedere ora alla misurazione dei campioni vocalici, avendo cura di rilevare almeno dieci campioni per ognuno dei sette foni vocalici principali (a, é, è, i, o, ò, u). Questi sette foni sono particolari della lingua italiana ed è chiaro che con parlanti di lingua differente si dovrà avere l’accorgimento di considerare foni diversi non presenti nel linguaggio italiano. Inoltre, la quantità di campioni misurabili è strettamente legata alla natura della registrazione. Se la registrazione della voce da comparare provenisse da una conversazione molto breve oppure molto degradata come qualità del segnale, potrebbe non essere possibile effettuare la rilevazione di un numero sufficiente di campioni vocali per un dato fono.
Per ciascun fono, misurati tutti i valori dei campioni, verranno calcolati i valori medi delle formanti (f0, f1, f2, f3). I valori medi emersi dall’analisi del parlatore noto e da quella del parlatore anonimo vengono confrontati per evidenziarne eventuali differenze o similitudini. Questo confronto non è però da solo sufficiente ad un corretto accertamento. Infatti, allo scopo di verificare se le eventuali differenze emerse tra i campioni rilevati siano o meno significative, occorre effettuare test statistici sui valori misurati, e verificare quali siano le differenze significative e quali invece non siano rilevanti a livello statistico.
Come ultima analisi, si utilizza un metodo totalmente automatico. Per fare questo confronto si utilizzano software di comparazione biometrica vocale automatica come ad esempio Easy Voice Biometrics, un programma che, a differenza di quanto il suo nome possa suggerire, è utilizzato in ambito forense professionale e comporta quindi un costo certamente non economico. Questo software, mediante sofisticati algoritmi di analisi vocale, stabilisce un grado di corrispondenza tra due voci in esame utile al riconoscimento del parlatore. La grande utilità di questi software si riscontra quando la perizia fonica riguarda una notevole quantità di file oppure quando sono da eseguire comparazioni incrociate tra più registrazioni. È possibile infatti aggiungere molteplici file alla comparazione ed eseguire test incrociati automaticamente. Ciò potrebbe essere di fondamentale importanza nel caso in cui i file oggetto di perizia siano presenti in quantità tali da rendere infattibile in termini di tempo l’analisi formantica semi-automatica.
Easy Voice Biometrics

I risultati della comparazione sono costituiti, come per i normali sistemi biometrici, dai valori di: uguaglianza (Matching), falsa esclusione (FR) e falsa accettazione (FA). Questo allo scopo di valutare l’affidabilità e la significatività statistica del risultato.
In conclusione, è bene ricordare che la valutazione relativa al riconoscimento di un parlante, soprattutto relativamente a intercettazioni e registrazioni, ambientali o telefoniche, di bassa qualità audio, non può essere espressa in modo assoluto. I limiti intrinseci dei reperti e le caratteristiche vocali permettono di ricondurre ad un parlatore in termini probabilistici. L’eventuale presenza, in un dato istante di tempo, di rumori impulsivi a largo spettro, voci sovrapposte o altri eventi, potrebbero compromette gravemente la possibilità di individuazione certa delle caratteristiche del parlante in tale istante. Dato il numero di variabili presenti nella registrazione e trattandosi in ogni caso di valutazioni biometriche e statistiche che presentano sempre una certa probabilità di errore, non si può garantire una certezza assoluta. Il tecnico non dovrebbe quindi esprimere una valutazione netta ma piuttosto dare un supporto alle ipotesi che le voci siano o non siano di un determinato parlante, fornendo dati statistici che avvalorino tali ipotesi.